Revolutionizing Video Generation with AI
| Input Image | Output Video |
|---|---|
 |
Stability AI has released Stable Diffusion Video, a groundbreaking foundational model for generative video. This model is a significant extension of their previous work in image models, specifically building upon the Stable Diffusion image model.
November 21
Stable Diffusion Video has been effectively used in a variety of applications. This includes auto-generated music videos that sync visuals with beats, text-to-video creations where scripts or descriptions are transformed into dynamic videos, and innovative projects using mov2mov technology to enhance or alter existing footage.
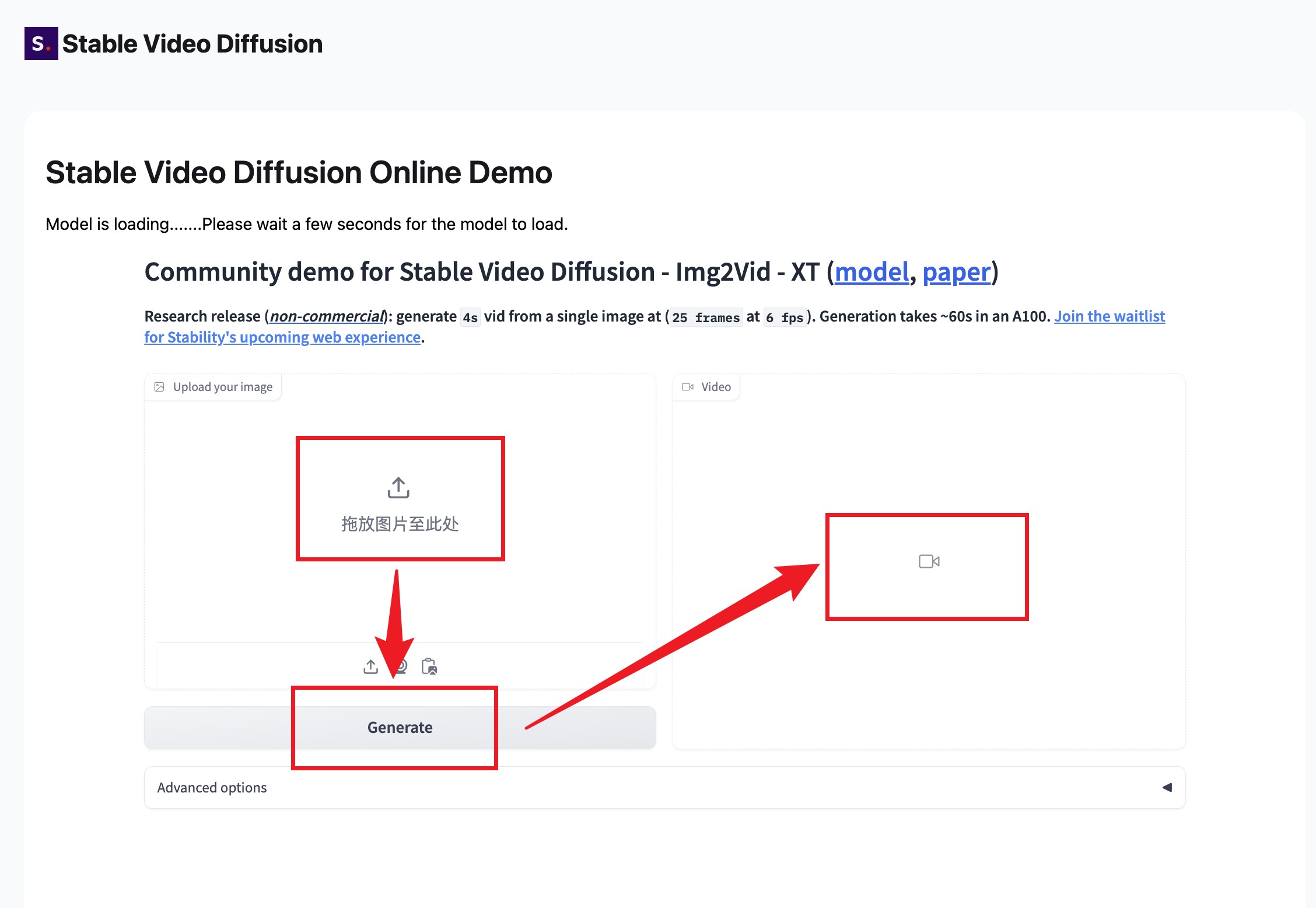
To use Stable Diffusion Video for transforming your images into videos, follow these simple steps:
Note: Stable Diffusion Video is in a research preview phase and is mainly intended for educational or creative purposes. Please ensure that your usage adheres to the terms and guidelines provided by Stability AI.
Stable Diffusion Video is a generative AI video model developed by Stability AI, based on the Stable Diffusion image model. It transforms static images into high-quality video sequences.
It offers high resolution, multi-view synthesis, and supports generating videos from a single image, suitable for various downstream tasks.
The code is available on Stability AI’s GitHub repository, and the weights required to run the model can be found on the Hugging Face page.
It is applicable in various sectors, including advertising, education, entertainment, etc.
It transforms 2D image synthesis models into generative video models by inserting temporal layers and fine-tuning on high-quality video datasets.
It supports customizable frame rates between 3 and 30 frames per second, with a resolution of 576×1024.
It was trained on millions of videos, most of which were sourced from public research datasets.
It surpasses leading closed models in user preference studies and is capable of multi-view synthesis.
Visit Stability AI’s website for detailed information on how to access and use the model.
It is currently for research purposes only, generates relatively short videos, and may not be entirely photorealistic.
Provide feedback via Stability AI’s social media channels or the contact options on their website.
It is currently not intended for real-world or commercial applications, but there may be developments in the future.
It emphasizes that the model is currently for research use only and requires users to adhere to specific terms of use.
It should not be used to create “factual” representations of people or events that are not true.
While there is potential risk, Stability AI emphasizes its current research nature and usage restrictions.
Misuse can be reported through the official channels of Stability AI.
Plans include improvements to the model, addition of new features, and potential developments for commercial applications.
It has the potential to simplify the video content creation process and provide new tools in fields such as art and education.
It is seen as an important milestone in the diversification of AI models.
Stability AI indicates plans to increase support for more languages and cultural adaptability.